In order to make a man or a boy covet a thing, it is only necessary to make the thing difficult to attain.
Introduction
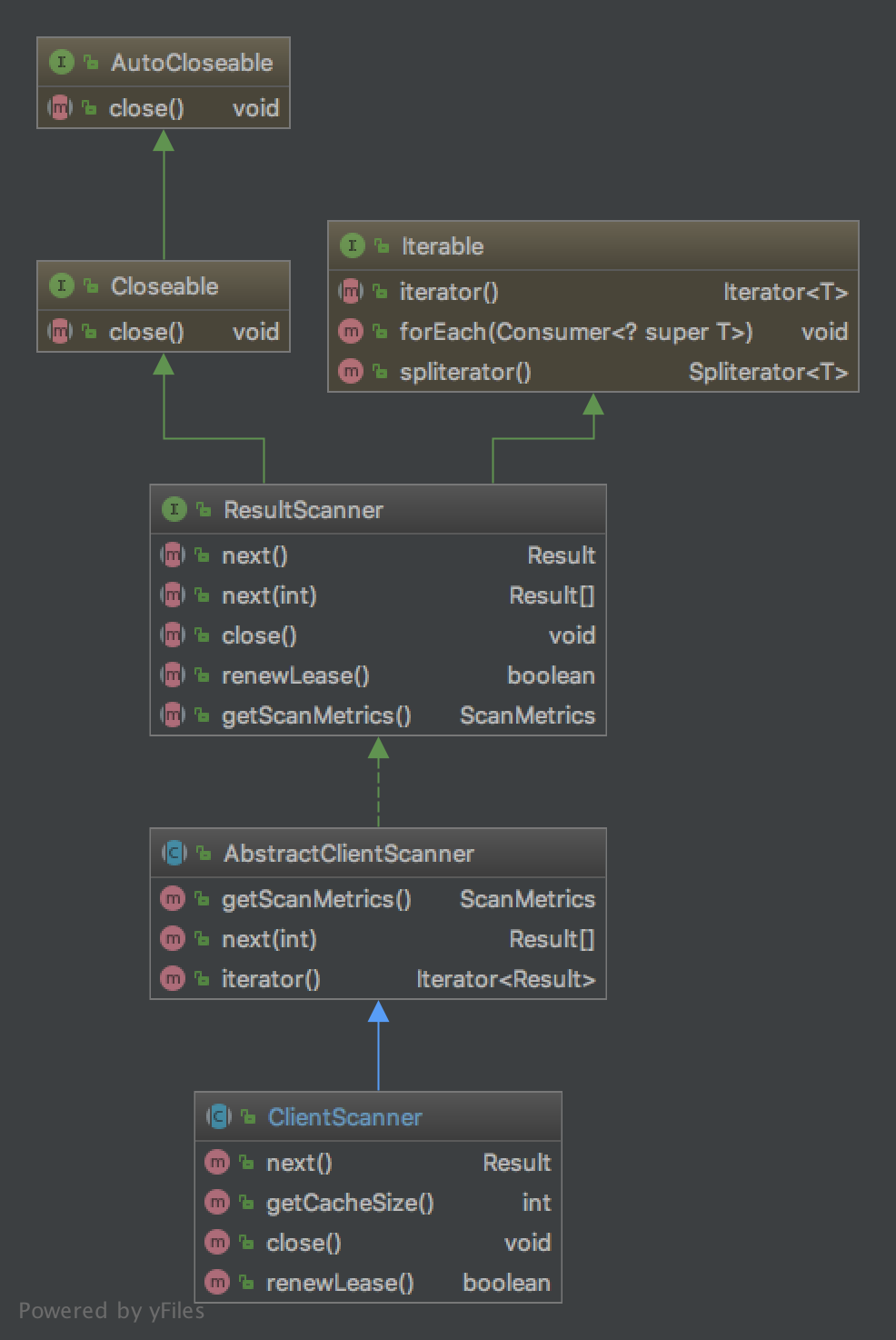
We often write client codes like below. In fact, ResultScanner has two implementations, one is ReversedClientScanner the other is ClientScanner which is current topic.
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result...
}
} finally {
rs.close(); // always close the ResultScanner!
}
ClientScanner UML
Prerequisite
Few important parameters and Scan options should be mentioned before going through codes, they can possibly enlighten us about tuning client side performance.
hbase.client.replicaCallTimeout.scan(1sec by default), time to wait for primary replica.hbase.client.retries.number(31 by default), max retries if operation fails.hbase.client.scanner.max.result.size(2MB by default), maximum number of bytes returned when calling a scanner’s next()hbase.client.scanner.timeout.period(60sec by default), client scanner timeout.hbase.client.scanner.caching(Integer.MAX_VALUE by default), number ofResultcache in ClientScannerScan#limit, limit of rows for this scanScan#maxResultSize, same tohbase.client.scanner.max.result.sizeScan#caching, same tohbase.client.scanner.cachingScan#metrics, metrics related to scan operations (both server side and client side metrics)Scan#cursorResult, cursor tells you where the server has scanned, it is a special result.
Process
Overview:  Detailed view of fetch results from server:
Detailed view of fetch results from server: 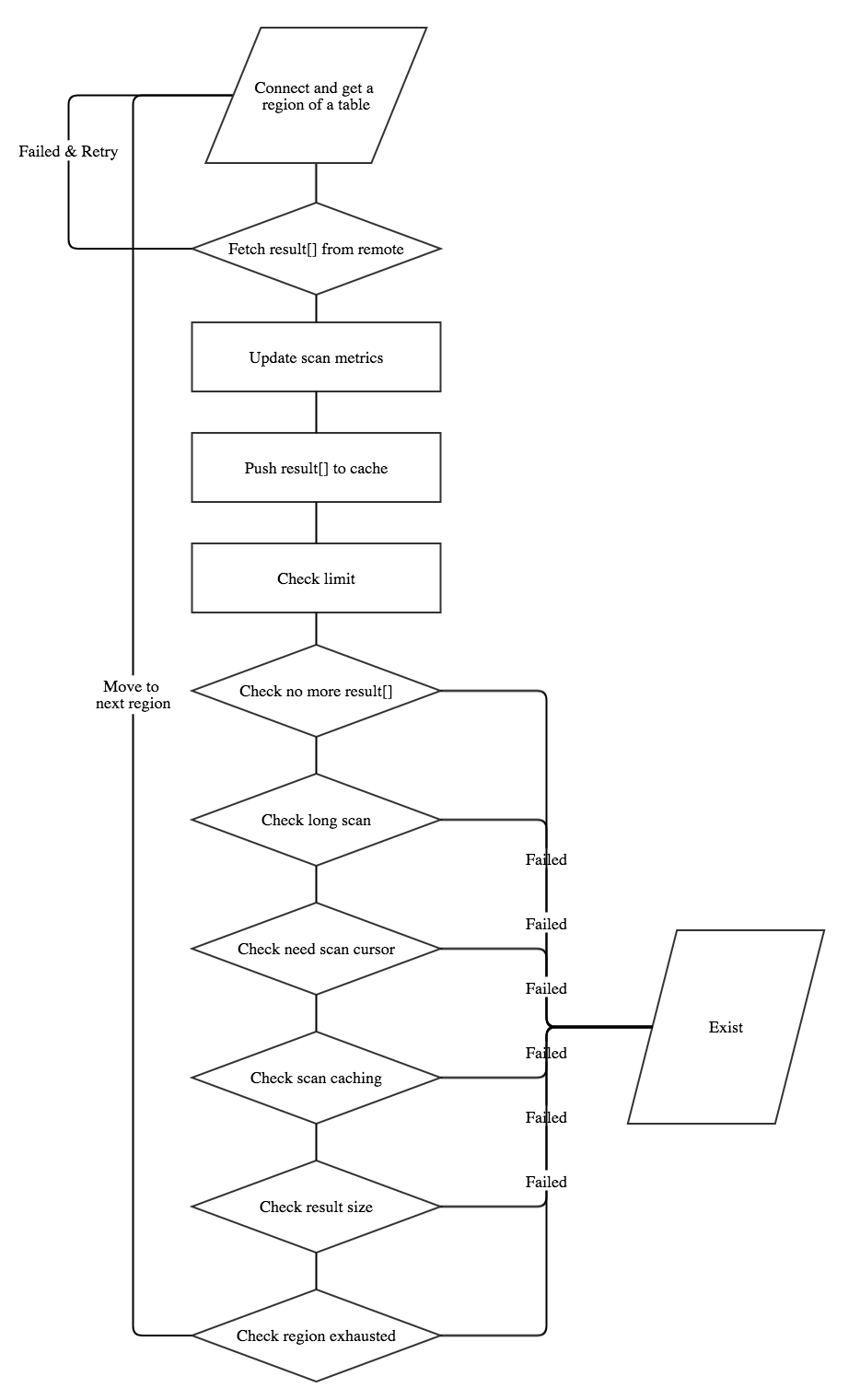
Cache
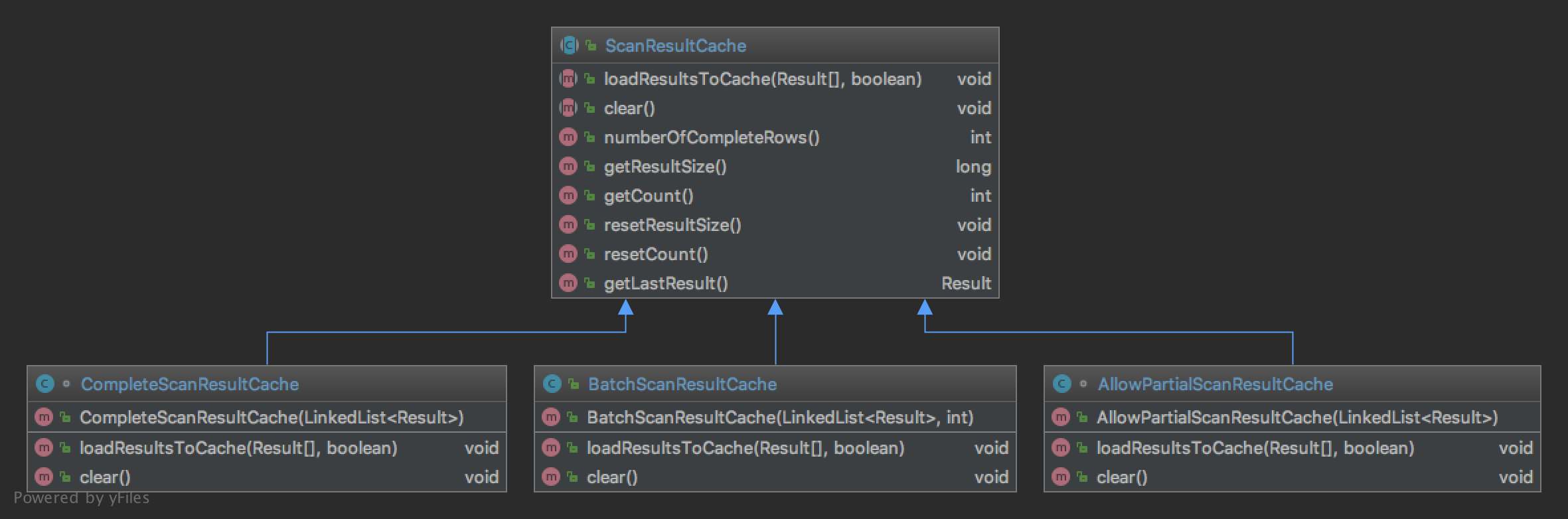 As pic shows, there are three kinds of
As pic shows, there are three kinds of ScanResultCache. It is not configured through configuration but depends on client Scan instance.
- If
Scanallows partial results, it will useAllowPartialScanResultCache. - If
Scandoesn’t allow partial results but set batch size, it will useBatchScanResultCache. - Not two cases above, it will use
CompleteScanResultCache.
Generally speaking, CompleteScanResultCache is used much more that others. But it has some bad effects on performance, since it will not exit until entire row fetched and cached, for large scan it will be time consuming, and client may suffer a long wait.
To use BatchScanResultCache, we should know that Result will be divided into batches which is set from Scan#setBatch(num), so the Result from next() may be partial, and the last patch size may not be the set batch num. (batch 5 means 5 cells in a Result)
AllowPartialScanResultCache is nearly the same to BatchScanResultCache except it is not batched, and can be random cells in a Result.
Tuning
- Default result size 2MB is too small to fit various application, choose the one that fits you best.
- Try to avoid using
CompleteScanResultCache, so you either set batch size or set allow partial after creatingScaninstance. - For advanced client, turn on
Scan#metricswill help you tune better. - If you scan a big table with many rows, try to turn on cursor in scan by
Scan#setNeedCursorResult(true), then callResult#isCursor()to judge if result it is cursor, if so, the cursor will let you know which row the server is scanning.
Thought
- Looks like Scan#limit is not respected, even check failed does nothing.
- The check process has some order issues, like checking scan cache and checking result size should be head of checking long scan.
- Codes of three types of
ScanResultCacheare worthy of reading, quite tricky.